바닐라 자바스크립트로 SPA 구현하기
리액트로 SPA를 만들고 동적라우팅으로 구성을 하면서 SPA가 뭐고 라우팅이 뭔지는 얕게 알게 되었으나 그게 실제로 어떻게 동작하는지 내부적인 부분은 알지 못했다. 바닐라 자바스크립트로 직접 구현해보면서 어떤걸 써서 그렇게 만들 수 있었던 건지를 알아보고자 한다 😗
이 글에 잘못 알고 있는 부분이 있을 수 있는데, 꼭꼭 말해주시면 감사하겠습니다…🙏🏻
Reference
구현 방법
- node.js, history API, vanila JS
SPA를 구현할 수 있는 방법으로는 history 또는 hash, 두 가지가 있고 두 가지 방법 모두 url이 변경될 때 페이지를 다시 로드하지 않는데 이 글에서 history를 사용하는 이유는 다음과 같다.
- url에 #이 붙는게 (=hash) 싫어서
- node.js로 간단히 서버를 만들어서 할 것이기에 서버측 지원이 필요한 history를 이용할 수 있어서
만약 존재하지 않는 페이지의 경로로 접근하면 Cannot GET / 어쩌고 이런류의 메세지를 화면에서 보게 된다. 이 때 우리가 흔히 아는 404 페이지 등을 보여주기 위해서는 다음과 같은 패키지를 설치하여 이용할 수도 있고, res.status(404).send('페이지를 찾을 수 없습니다'); 이렇게 미들웨어를 직접 작성해서 사용할 수도 있다.
express-error-handlerhttp-status-codes
서버 만들기
우선 간단하게 서버를 만들자. 프로젝트에 express를 설치한다. 그리고 server.js를 만들어서 서버를 만든다. 📎예전에 node.js 아주 살짝 찍먹했던 글을 같이 적어놔본다 ㅎ 기억을 더듬기에 딱이었다.
const express = require('express');
const path = require('path');
const app = express();
app.listen(process.env.PORT || 3000, () => console.log('Server running...'));
// run server by node server.js어쨌든, 서버를 만들고 나면 이제 두 가지 설정을 해줘야 한다.
-
정적 폴더 경로 설정해주기
이미지, html, css, javascript와 같은 정적 파일을 전송하기 위해 설정해야 한다. 자세한 것은 📎express 공식문서를 참고하자. frontend라는 폴더를 만들었고, 그 폴더의 경로를 설정해준다.app.use( '/static', express.static(path.resolve(__dirname, 'frontend', 'static')) );이렇게 정적 경로를 지정해주고나면 첫번째 인자 값으로 경로를 퉁칠수 (?)있다.
../../js/index.js이런식으로 쓰는게 아니라 그냥 바로/static/js/index.js이렇게 써줄 수 있다. 그리고 이렇게 안 쓰면 어차피 에러가 난다 ^^… 이걸 진행하면서 겪었던 에러의 50%는 다 경로문제였던 기억이 있다. 항상 경로에 주의하자. 이런 정적 경로를 설정할 때에는 사용자가 주소창에 입력해서 접근하지 못하도록 숨기는 방법도 있는데, 이 글에서는 거기까지는 다루지 않을 것이다. -
브라우저에서 보내는 GET요청에 응답하기
사용자가 주소창에 입력하는 것은 node.js서버에 get요청으로 들어오게 된다. 서버를 처음 만든 후 이 설정을 해주지 않는다면Cannot GET /파티를 보게 된다. 이 글에서 구현하고자 하는 SPA를 위해서 모든 경로에 동일한 응답을 주게끔 아래와 같이 설정할 수도 있고,// 어떤 요청이 들어오든 다 index.html을 전송한다 app.get('/*', (req, res) => { res.sendFile(path.resolve(__dirname, 'frontend', 'index.html')); });필요한 경로만 지정하고 그 외에 발생할 수 있는 에러에 대해서는 따로 에러페이지를 보내줄 수도 있다. 이 부분은 위에서 언급했던 패키지를 쓰거나 미들웨어를 직접 작성하면 된다. 전송할 에러페이지는 마찬가지로 정적 폴더 안에 넣으면 된다.
// 필요한 경로에만 설정함 app.get('/', (req, res) => { res.sendFile(path.resolve(__dirname, 'frontend', 'index.html')); }); app.get('/detail', (req, res) => { res.sendFile(path.resolve(__dirname, 'frontend', 'index.html')); }); // 파라미터도 설정할 수 있다. app.get('/detail:id', (req, res) => { res.sendFile(path.resolve(__dirname, 'frontend', 'index.html')); });이 글에서는 첫 번째 방법을 이용할 것이다. 왜냐면 이 라우팅 처리는 바닐라 자바스크립트로 직접 구현할 것이기 때문에…🐞
여기까지 했으면 서버에서 해줄 것은 끝났다. 더 완성도 있게(?)하려면 에러처리등 신경 써줘야 하는 것이 더 있긴 하지만.. 일단 이 글의 목적인 프론트엔드 SPA 구현에 집중하자.
Router 만들기
일단 라우터가 뭔지 알아야 한다. 리액트 프로젝트를 하면서 바뀌는 url에 맞게 콘텐츠를 보여주는 기능이라고 경험적으로만 알고 있었지, 정확하게 알고있었냐 하면…🤔
라우터를 정보처리기사 필기시험 느낌으로 설명하면,
네트워크와 네트워크 간의 경로(Route)를 설정하고 패킷의 송수신을 담당한다. 가장 빠른 길로 트래픽을 끌어주는 장치
라고 할 수 있을 것 같다. 갑자기 장치?? 기계?? 하드웨어?? 싶지만… 결국 컨셉은 똑같은 것 같다. 이게 웹 어플리케이션에서는, 리액트에서는 써드파티앱으로 라이브러리로 설치해서 사용해왔던 것이다.
그리고 우리는 바닐라 자바스크립트로 history API를 이용해 라이브러리를 사용하는 것이 아니라 직접 구현해볼 것이다. 위에서 잠깐 이야기했던 history API에 대해 다시 알아보자.
history API
📎MDN DOM의 Window 객체는 history 객체를 통해 브라우저의 세션 기록에 접근할 수 있는 방법을 제공합니다. history는 사용자를 자신의 방문 기록 앞과 뒤로 보내고 기록 스택의 콘텐츠도 조작할 수 있는, 유용한 메서드와 속성을 가집니다.
window의 history 객체를 이용할 수 있게 하는 API이다. url창에 사용자가 입력한 주소들은 일종의 주소록에 보관되는데, 그 주소록을 다룰 수 있게 하는거라고 이해했다. 즉, 뒤로가기 했을 때 이전 페이지가 로드되고 하는 것은 주소록 안에서 저장되어 있는 이전 주소를 불러오기에 가능한 것이다.
그럼 결국 주소록 안에 주소를 추가해야한다. 이 역할을 pushState() 메소드가 해주고, SPA를 구현하기 위해 이용할 것이다.
router.js 파일을 만들어서 그 안에 라우터를 만들 것이다. 파일 이름은 App.js도 index.js도 괜찮은 것 같다. 만들었으면 index.html과도 연결해준다.
body 맨 밑에 둬도 되지만, 나는 좀 더 빨리 렌더링이 진행되게 하고 싶어서 head안에 defer옵션을 설정하여 스크립트를 삽입했다. 만약 옵션을 따로 설정하지 않을 거라면 DOMContentLoaded이벤트 등을 이용해서 초기 스크립트를 실행시켜야 한다.
<script src="/static/js/index.js" type="module" defer></script>router 함수를 만들어서 우선 현재 url을 제대로 읽어들이는지부터 확인해보자. location.pathname을 이용할 것인데, 마찬가지로 window 객체이고 지금 당장 크롬을 열어서 콘솔 창에 location이라고 입력해보면 객체를 확인할 수 있다. 그중에서 pathname이라는 프로퍼티는 현재 url의 /뒤를 보여준다. 자세한 것은 📎MDN에서 확인할 수 있다.
코드를 부분부분 잘라서 글을 작성했는데, 사실은 부분부분 설명을 작성함으로써 내가 한 번 더 이해하기 위함이다 (?)
const router = async () => {
const routes = [
{ path: "/", view: () => console.log("route page") },
{ path: "/main", view: () => console.log("main page") },
{ path: "/detail/:id", view: () => console.log("detail page") },
];이 웹에서 이용할 경로들을 적어준다. view는 해당 경로일 때 그려낼 html을 의미하는데, 일단은 콘솔로그를 찍어보는 것으로 대체한다. 배열의 인자 하나하나를 route (경로) 라고 부를 것이다.
const potentialMatches = routes.map((route) => {
return {
route: route,
isMatch: location.pathname === route.path,
};
});map을 이용해서 각 route들을 객체로 출력한다. route 프로퍼티에는 위에서 봤던 객체를 담고, isMatch 프로퍼티에는 현 url과 일치하는지를 확인한다. 예를들어 /에서는 path가 /인 것의 isMatch가 true로 반환되고 /main에서는 path가 그와 동일한 두번째 객체의 isMatch가 true로 반환된다. 콘솔에 찍어보면 다음과 같은 배열을 볼 수 있다.
(3) [{…}, {…}, {…}]
[
{
"route": {
"path": "/"
},
"isMatch": true
},
{
"route": {
"path": "/main"
},
"isMatch": false
},
{
"route": {
"path": "/detail/:id"
},
"isMatch": false
}
]let match = potentialMatches.find((potentialMatch) => potentialMatch.isMatch);그래서 그중에서 isMatch가 true인 값을 뽑아낼 것이다. find메소드를 활용한다. 이 메소드는 주어진 함수를 통과하는 첫번째 요소의 값을 반환하는데 없으면 undefined를 반환한다. 지금 쓰면서 드는 생각인데 undefined가 반환되는 것을 이용해서 에러 핸들링을 해볼 수도 있을 것 같다.
if (!match) {
match = {
route: routes[0],
isMatch: true,
};
}route에 정의된 곳으로 이동하지 않는다면 기본값으로 되돌린다. 원래 사람이 기본값을 첫번째로, 순서대로 쓰고 그러잖아요? ㅎㅎ… 그래서 루트 경로 (/)가 첫번째라서, routes[0]으로 설정했습니다.
if (!match) {
document.querySelector('#app').innerHTML = `<h1>404</h1>`;
return;
}만약 기본값으로 되돌리는 게 아니라 없는 페이지에 접근하려 하는 것이니까 에러메세지를 보여주고 싶다하면 다음과 같이 할 수 있다. 위에 쓰다가 생각나서 실험해보고 왔는데 잘 된다.

console.log(match.route.view());
};
router();특정 pathname에 위치한다면 그것에 일치하는 함수를 실행하게 한다. 우리는 지금 console.log를 적어놨으니까 이게 실행될 것이다.
이렇게 하면 일단, url의 변화에 따라 각기 다른 view를 실행하는 라우터가 완성되었다. 계속해서 다듬어보자.
pushstate()
아까 얘기했던 pushState()를 사용해서 브라우저의 주소를 바꿀 것이다. history API를 통해 접근할 수 있는 window의 이벤트로, window를 생략하고 그냥 pushState() 로만 쓸 수도 있다.
뒤로가기를 눌렀을 때 url만 바꿔줄 뿐 다시 렌더링을 해주지는 않는다. (router를 다시 동작시키지 않음) 이에 주의해야 한다. 새로고침도 마찬가지이다.
pushState는 state, title, url 세 개의 인자를 받는다.
pushState(state, title, url);-
state : 새로운 세션 기록 항목에 연결할 상태 객체. 새로운 데이터 객체를 의미한다. 저장해야할 데이터가 없다면 null 또는 빈 객체를 전달한다.
-
title : 보통 빈 문자열을 지정한다. 현재 대부분의 브라우저가 title을 무시하기 때문. 또는 state에 대한 짧은 제목을 제공하는 용으로 쓰기도 한다.
-
url : (optional) 새로운 세션 기록 항목의 url. 즉 이동하고 싶은 url. 현재 url과 같은 출처를 가져야 하며 지정하지 않는 경우 문서의 현재 url을 사용한다. 주의할 점은 pushState() 호출 이후에 브라우저는 주어진 URL로 탐색하지 않는다는 것.
그래서 결국, 우리는 이 pushState()라는 메소드를 현 url을 원하는 경로로 바꾸는데 사용할 것이다. router 함수 외에 다음의 함수를 작성한다.
const navigateTo = (url) => {
history.pushState({}, null, url);
// pushState()가 다시 렌더링까지는 해주지 않으므로, view를 호출하는 router를 실행시키게 한다.
router();
};이 함수는 url을 이동해야하는 상황에 사용할 수 있다. 예를 들어 네비게이션 바에서 특정 메뉴를 눌렀을 때 이 함수가 실행되어, 해당 메뉴에 대한 뷰로 (페이지로) 이동하게 만든다고 생각하면 된다.
그런데 문제는 그럴때 우리가 제일 많이 사용하는 a태그의 href 속성은 새로고침이 발생한다는 것이다. 따라서 새로고침이 발생하지 않도록 a태그의 기본 기능을 먼저 막아야 한다. 그럼 굳이 a태그를 왜 쓰냐 싶을 수도 있는데 결국 경로를 편하게 관리하기 위함이라고 생각했다. 각각의 요소가 이동할 경로(?)를 href에 담고 있다고 암시적으로… 암묵적으로…? 합의된 느낌…?
이를 위해 아래 코드를 작성할 것인데, 새로고침 없이 페이지 이동이 가능함을 확인할 수 있다.
document.addEventListener('DOMContentLoaded', () => {
document.body.addEventListener('click', (e) => {
//이벤트 위임을 위해 작성하는 코드
//data-link라는 data attribute를 가진 링크에만 작동하도록 조건문을 작성해 이벤트를 위임한다
if (e.target.matches('[data-link]')) {
// 링크가 기본으로 가지고 있는 동작을 멈춰서 새로고침을 방지한다
e.preventDefault();
// 그리고 페이지 콘텐츠 변경 및 path 이동을 위해 우리가 만든 함수를 대신 실행한다
// 링크가 가진 href를 url로 삼아서 함수를 실행한다
navigateTo(e.target.href);
}
});
router();
});물론 이렇게 되면 링크를 연결할 때마다 data-link라는 데이터 속성을 까먹지 않고 꼭 넣어줘야 한다는… 불편함이 있다 😅 더 좋은 방법이 있는지 궁금하다.
이제 여기까지 하면, 지금까지 완료된 것은 다음과 같다.
- 현재 url이 라우트 목록 중 무엇과 일치하는지 확인하고, 그에 맞는 html을 끌어다주는 라우터 만들기
- 새로고침이 발생하는 a링크 대신 사용할, url을 변경시켜주는 함수 만들기
한번 서버를 열어서 테스트해보면… 네비게이션을 클릭할 때마다 새로고침이 발생하지도 않고, 아직 view를 등록하지는 않았지만 해당 라우트에 맞는 콘솔로그가 잘 찍히는 것을 확인할 수 있다.
그런데 문제가 한 가지가 있다. 뒤로가기 또는 앞으로가기를 눌러보면 화면이 바뀌지 않는다 🙄 이 문제를 popstate이벤트를 이용해서 해결할 것이다.😎
popstate
먼저 popstate가 뭘까.. MDN에서는 다음과 같이 말하고 있다
Window 인터페이스의 popstate 이벤트는 사용자의 세션 기록 탐색으로 인해 현재 활성화된 기록 항목이 바뀔 때 발생합니다. 만약 활성화된 엔트리가 history.pushState() 메서드나 history.replaceState() 메서드에 의해 생성되면, popstate 이벤트의 state 속성은 히스토리 엔트리 state 객체의 복사본을 갖게 됩니다.
history.pushState() 또는 history.replaceState()는 popstate 이벤트를 발생시키지 않는 것에 유의합니다.popstate 이벤트는 브라우저의 백 버튼이나 (history.back() 호출) 등을 통해서만 발생된다.
말이 너무 어렵다. 간단 요약하자면 결국 pushState() 메소드에 의해 발생하지는 않지만 뒤로가기 버튼을 클릭하면 발생하는 이벤트정도로 생각할 수 있을 것 같다.
결국 potstate 이벤트가 발생할 때마다 router 함수를 호출하면, router 함수는 view를 그려내는 것을 포함하고 있으니 뒤로가기 버튼을 눌렀을 때 화면이 변하지 않는 문제점을 해결할 수 있을 것 같다.
아래와 같이 코드를 작성해 이벤트를 붙이고 이벤트 발생시 router 함수가 실행되게 만들어주자.
window.addEventListener('popstate', router);View 만들기
이제 라우터, 라우트와 관련된 부분은 대강 끝이 났다. 파라미터를 이용한 동적라우팅은? 싶다면 그건 저~아래에서 다시 다룰 것이다.
그전에 먼저, 콘솔로그 대신 html을 렌더링하게 해보자.
페이지가 아니라 view라고 부르는 것은 우리가 구현할 것이 SPA이기 때문이다. single page라는 의미를 담고 있는데 각 라우트마다 페이지가 있다고 말하는 것은 이상하니까 😔
그동안 리액트나 뷰 공식문서에서 왜 view라고 하는지 궁금했었는데 직접 만들어보니까 확 와닿으면서 알게되었다. 결국 보여지는 부분을 갈아끼우면서 렌더링하는 것이니 view라는 이름이 더없이 적절했다.
기본 템플릿 만들기
AbstractView.js로 기본 템플릿이 될 class를 만든다. 모든 view들은 이 class를 상속받아 확장해서 작성될 것이다. Template같은데 왜 AbstractView라고 이름을 지은걸까 궁금했는데 그냥 Abstract Class라는 개념이 있더라.
📎abstract에 대한 생활코딩 글
abstract라는 것이 상속을 강제하는 일종의 규제라고 생각하자. 즉 abstract 클래스나 메소드를 사용하기 위해서는 반드시 상속해서 사용하도록 강제하는 것이 abstract다. … 추상 메소드란 메소드의 시그니처만이 정의된 비어있는 메소드를 의미한다.
추상이라고 하니까 말만 들어도 어렵다 ㅎ
각각의 view만들기
먼저 AbstractView를 만든다. 지금 당장 필요한 게 라우트별 HTML을 그리는 것이니까 이에 대한 함수 하나를 만들고, 이왕이면 문서의 제목까지 라우트에 맞춰서 변경시켜주면 더 좋을 것 같다.
// 모든 view가 상속받을 일종의 템플릿 같은 것을 만든다.
export default class {
constructor(params) {
this.params = params;
}
/**
*
* @param {String} title 문서의 제목을 변경한다
*/
setTitle(title) {
document.title = title;
}
async getHtml() {
return '';
}
}그리곤 AbstractView에서 상속받아 확장하는 각각의 view를 만든다. 라우트별로 만들어주자.
import AbstractView from './AbstractView.js';
export default class extends AbstractView {
constructor() {
super();
this.setTitle('Dashboard');
}
/**
*
* @returns app div에 그려낼 해당 view의 html을 반환합니다.
*/
async getHtml() {
return `
<h1>초기 페이지입니다</h1>
<p>
Lorem ipsum dolor sit, amet consectetur adipisicing elit. Enim dolore quia
voluptate odio corporis aliquid? At adipisci labore eligendi rerum qui
numquam tempora molestiae porro! Maxime hic aperiam sit eligendi?
</p>
<nav class="nav">
<a href="/" class="nav__link" data-link>초기페이지</a>
<a href="/main" class="nav__link" data-link>코스</a>
</nav>
`;
}
}여기까지 했을 때 폴더 구조가 대체 어떻게 돌아가는 건지 궁금할 수 있을 것 같은데 (=나) 다음과 같다. 중간 점검차 경로들을 아까 처음에 설정했던 정적 경로로 제대로 썼는지 확인하자… 안 하면 에러의 원인이 된다 😇
- 📂 frontend // 프로젝트의 route 경로에 위치해있다.
---- 📂 js
------- 📂 view
----------- 📄 AbstractView와 각각의 View 파일들
------- 📄 router.js
---- 📂 css
------- 📄 index.css와 각각의 view별 css파일들
---- 📄 index.htmlview를 라우터와 연결하기
다시 router.js로 돌아와서, 못생긴 console.log 대신 view를 그려낼 수 있게끔 각각의 view 파일들을 import하고 연결해주는 코드를 작성한다.
// console.log를 뷰로 바꿔치기 해준다.
const routes = [
{ path: '/', view: Dashboard },
{ path: '/main', view: Main },
{ path: '/detail/:id', view: Detail },
];
// view가 class이기 때문에 new 생성자를 사용해서 새 인스턴스를 만든다
const view = new match.route.view();
document.querySelector('#app').innerHTML = await view.getHtml();여기까지 하고 실행했을 때 나는 이런 에러를 마주했었다. 이 에러를 정~~~~~~~~~~말 많이 봤는데 보통 경로 문제였다.
Dashboard:1 Failed to load module script: Expected a JavaScript module script but the server responded with a MIME type of “text/html”. Strict MIME type checking is enforced for module scripts per HTML spec.
경로 문제도 원인이 다양한데, 이걸 기록했을 때의 원인은 확장자였다. 내 prettier, eslint 설정에서는 import를 할 때 .js 를 따로 붙이지 않는데, 그렇다보니 발생하는 문제였다. import할 때 경로에 .js 라는 확장자명을 추가해주었다. 만약 import AbstractView from "./AbstractView"; 로 했을 때 AbstractView가 폴더였고 그 안에 index.js가 있었으면 상관없었을 텐데, 지금은 폴더가 아니라 단일 파일(?)이어서 파일 확장자명을 명시해준다.
동적라우팅
이제 바뀌는 라우트에 따라 적절한 뷰도 그려지는 것을 확인할 수 있다. 남은 것은 동적라우팅과 자바스크립트 연결인데, 동적라우팅이 제일 복잡했다…😂
리액트에서 했던 것처럼 바닐라 자바스크립트도 :id로 파라미터를 작성한다. /some/:id 형식으로 들어왔는지 확인하기 위해 정규표현식을 작성한다. 정규표현식은 📎요 사이트에서 무슨 뜻인지 확인할 수도 있고 이것저것 수정해보며 가지고 놀 수 있다. 직접 하는 것이 이해에 직빵이다.
replace(정규표현식, 대체할 값) 이 자바스크립트 메소드는 첫번째 인자에 해당하는 문자열을 두번째 인자 또는 함수의 반환값으로 변경할 수 있다. 이 글에서는 정규표현식을 사용한다.
// 정규식 객체를 생성한다
const pathToRegex = (path) =>
new RegExp('^' + path.replace(/\//g, '\\/').replace(/:\w+/g, '(.+)') + '$');
console.log(pathToRegex('/posts/:id')); // /^\/posts\/(.+)$/potentialMatch함수의 isMatch부분을 다음과 같이 수정한다.
const potentialMatch = routes.map((route) => {
return {
route: route,
result: location.pathname.match(pathToRegex(route.path)),
};
});match메소드는 배열을 반환하는데, 정규식과 문자열이 일치하면 전체 문자열을 배열의 첫 번째 요소로 가진다. 그리고 만약 정규식에 ()로 감싸진 부분이 있다면 이를 캡쳐링 그룹이라고 하는데 캡쳐링 그룹에 해당하는 문자열이 두 번째 요소로 들어간다.
아래 코드에서 확인할 수 있다. 즉, 이를 이용하면 동적라우팅에서 매번 변화하는 패스파라미터 부분을 분리하기 쉽다. 이렇게 한 뒤에는 potentialMatch라는 이름보단 routeWithParam같은 이름이 더 잘어울릴 것 같다…
console.log('/posts/2'.match(/^\/posts\/(.+)$/)); // [ "/posts/2", "2" ]만약 캡쳐링 그룹에 더 자세하게 알고 싶다면 mdn 문서나 rhostem님의 포스트를 추천한다.
view에 파라미터를 전달하기 위해 파라미터를 가져오는 함수를 작성한다. 배열에서 두번째 값이 파라미터이므로, 이를 가져오는 역할을 한다.
const getParams = (match) => {
// ["/posts/2", "2"]; 에서 id값에 해당하는 두 번째 값을 가져옴
const values = match.result.slice(1);
const keys = Array.from(match.route.path.matchAll(/:(\w+)/g)).map(
(result) => result[1]
);
console.log(Array.from(match.route.path.matchAll(/:(\w+)/g)));
return {};
};
//요 함수가 console에 찍어내는 배열은 다음과 같다.
[[":id", "id"]];
0: Array(2)
0: ":id"
1: "id"
groups: undefined
index: 9
input: "/detail/:id"
// 임시였던 return {}; 는 다음과 같이 수정해준다. 역시 console.log로 찍어가보면서 이게 뭔 역할을 위함인지 확인하며 작업한다.
return Object.fromEntries(
keys.map((key, i) => {
console.log([key, values[i]]); // ["id","2"]
return [key, values[i]];
})
);
자바스크립트 연결하기
path에 따라 그에 맞는 스크립트가 실행되게 하기!
의외로 가장 많이 머리가 아팠던 부분이다. 지금부터 소개하는 내용은 삽질기록이다…😂
엥 그거 그냥
index.html에 필요한 자바스크립트 파일<script>태그로 다 때려박으면 되는거 아니냐 🤔
라고 생각하는 사람이 있을까? 있다면 나와 영혼의 쌍둥이일 것이다…
🎯 뭐가 문제였냐
일단 호출하고자 하는 view별 자바스크립트 파일을 편의상 mainView.js라고 해보겠다.
우리가 구현하는 SPA 는 초기 index.html이 깡통으로 온다. <div> 하나만 들어있는데, 접속한 url에 따라 라우터가 판별해서 그에 맞는 뷰를 저 div 안에 그려낸다.
근데 그런 깡통에 자바스크립트 파일을 다 때려박으면, 없는 html 요소에 이벤트를 붙이려 하니까 당연히 에러가 뜬다. 에러 메세지를 확인해보면, 전부 null에는 이벤트 리스너를 붙일 수 없다는 식의 에러들이었다.
어떻게 해결했냐
1. router에서 스크립트를 실행시키기
그래서 생각했던게 url을 변경해 이동할 때마다 router 함수가 실행되고 있으니까, 그 안에서 view를 그리는 코드 뒤에 자바스크립트를 실행시키자는 것이었다.
router.js에서 뷰를 그려내니까 뷰를 그려내고 그 후에 mainView.js를 호출할 수 있도록 다음의 위치에 작성해봤다. 호옥시 DOM 로드만 완료되면 실행되는 이벤트인 DOMContentLoaded 탓일까봐 load 이벤트도 걸어봤다.
// router 함수에서 뷰를 그려내는 부분
document.querySelector('#app').innerHTML = await view.getHtml();
// 그래서 여기에
window.addEventListener('load', () => {
// mainView.js들을 호출해봄
});여전히 null에는 이벤트 리스너를 붙일 수 없다고 떴다. 이게 아닌가보다.
2. html에 스크립트 태그를 동적으로 추가하기
그렇게 삽질을 하다가… 처음부터 html 안에 스크립트를 넣는 것이 아니라, path에 따라 동적으로 <script> 태그를 추가하면 어떨까? 하는 생각이 들었다.
그래서 작성한 코드
document.querySelector('#app').innerHTML = await view.getHtml();
const isScriptExists = !!document.getElementById('viewScripts');
if (!isScriptExists) {
const script = document.createElement('script');
script.src = '/js/Scripts.js';
script.type = 'module';
script.id = 'viewScripts';
document.body.appendChild(script);
}if문이 없으면 라우터 함수가 실행될 때마다 스크립트 태그가 이미 있는데도 계속 추가된다. 그런 일이 발생하지 않도록 스크립트 태그가 이미 존재한다면 추가하지 않게 조건문을 작성했다.
스크립트 태그가 이미 존재하는지를 확인하기 위해서 스택오버플로우를 뒤져봤는데 어떤 천사가 다양한 방법의 각 장단점까지 비교해둔 답변을 작성한 것을 보았다. 📎해당 글 보러가기 내 상황에선 id 셀렉터를 이용하는 것이 맞다 생각되어서, id 셀렉터를 이용해 특정 스크립트 태그가 존재하는지를 판단했다.
근데 이 방법은 아주 심각한 문제가 있었다.
해당 라우트에 두 번째로 접속할 경우에는 스크립트를 이미 읽었다 생각하고 다시 실행시키지 않았다.
- 처음
/에 접속했을 때 : 스크립트 잘 실행됨 - 그 다음으로
/detail에 접속했을 때 : 스크립트 잘 실행됨 pushState로/로 변경하고 라우터가 다시 랜더링 했을 때 : 스크립트 실행되지 않음 🚨
3. 해결
그래서 난 다시 고민에 빠졌다. 잘 되는줄 알았는데 저런 심각한 문제가 있었다니.. 근데 또 각각의 view별 자바스크립트가 대충 재현하자면 이렇게 생겼었는데
// mainView.js
// #1 여기서 querySelector로 html 요소들을 불러와서 변수에 할당하고
const ul = document.querySelector('.main-ul');
...
// #2 그것들을 활용하는 함수들을 작성하고
const getData = async () => {
}
...
// #3 순서를 정리해보니까 init 함수를 하나 만들어서 맨 처음 실행되어야 하는 것들, 예를 들면 이벤트 리스너 붙이기 등을 넣어주고
const init = () => {
ul.addEventListener('click',getData);
...
}
// #4 init함수만을 default로 export 하면 mainView.js를 호출했을 때 잘 돌아가는 파일이었다.
export default init;#1에서 자꾸 null이 뜨는 것 같아서, #1에서 DOM 요소를 변수에 할당하는 부분과, 스크립트가 실행되는 부분과 (init함수가 호출되는 부분), router.js에서 스크립트들을 import하는 부분들 등 각각이 어떤 순서로 실행되는지를 알아야겠다 싶었다.
그래서 콘솔로그를 다 찍어봤고 다음과 같은 결과를 얻었다.
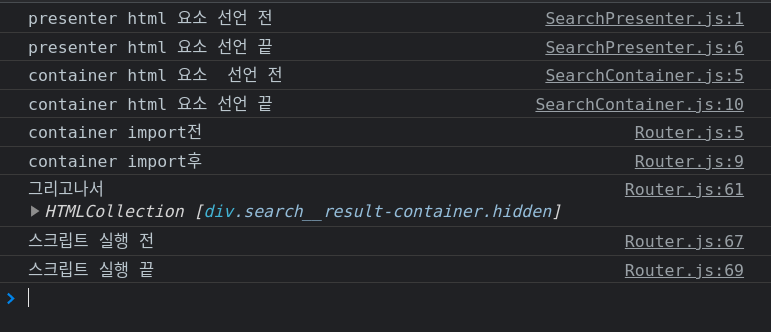
그래서! 결국 어떻게 해결했냐면
- 전역으로 선언했던 DOM 요소들을 각각의 함수 안으로 넣어줬다.
- 그리고 다음과 같이
router.js에서 스크립트를 호출했다.
// 여기서 뷰를 그리고 이 다음 줄에 다음 코드들을 작성함
const routeRegex = new RegExp(/^\/$/);
// 대충 이런 정규표현식 객체들을 만들고
// 현 path를 구하고
const path = location.pathname + location.어떤파라미터;
// 정규표현식으로 검사해서 true라면 그에 해당하는 스크립트를 호출
routeRegex.test(path) && mainView();근데 다시 생각해보면… 굳이 정규표현식 객체를 만들 필요가 없었다. /list와 /list?search=와 /list/3을 구분하려고 정규표현식 객체를 만들었던 건데, 그냥 미리 만들어두었던 pathToRegex 함수를 사용하면 된다. 이 함수는 /list?search=는 인지하지 못하지만, /list?search=와 /list는 사실 같은 스크립트를 실행하고 있기 때문이다.
따라서 마지막으로 다음과 같이 수정한다. 라우트별로 실행할 스크립트 파일도 routes 객체 안에 넣으므로 match를 통해서 실행을… 뭐라고할까 자동화(?)할 수 있기 때문에 훨씬 깔끔해진다.
const router = async () => {
const routes = [
{ path: "/", view: 해당하는 뷰, script: 스크립트 실행하는 함수 },
{ path: "/main", view: 해당하는 뷰, script: 스크립트 실행하는 함수 },
{ path: "/detail/:id", view: 해당하는 뷰, script: 스크립트 실행하는 함수 },
];
...
// run script
match.route.script();이제 아주 잘 된다 😎

소감
그냥 라이브러리 쓰면 되는거 아니야?가 아니라 직접 만들어보니까 라우터가 뭐고 어떻게 돌아가는지 더 잘 이해되고 뿌듯하고 그렇다. 너무 즐거운..프로젝튼가 이거? 프로젝트였다.- 이벤트 위임부터 더 안 쓰는 이벤트를 지워야 하는 이유를 공부할 수 있었다. 글로 정리하려고 쓰고 있는데 오.. 길어지고 있다.
DOMContentLoaded랑load의 차이, 브라우저 렌더링의 과정에 대해 공부할 수 있었다. 얘네도 글로 정리하고 있는데 오래걸릴 것 같다.- 그리고 진짜 자잘자잘한 것들도 다시 확인하고 공부하고 하느라 시간이 배로 걸렸다. 넘 뿌듯하다.
- 무엇보다도 라이브러리가 정말 개발을 편하게 만들어주는 도구들이라는 것을 깨달았다. 진짜… 엄~~~~청 많은 일들을 대신 해주는 거였다 ㅋㅋㅋㅋ